You might be surprised to learn that one small text file, known as robots.txt, could be the downfall of your website.
If you use it incorrectly you could end up telling search engine robots not to crawl your entire website, which means it won’t appear in search results. Therefore, it’s important to understand the purpose of a robots.txt file, how to check it and how to implement it correctly.

What is robots.txt?
A robots.txt file tells web robots, also known as crawlers, which pages or files the domain owner doesn’t want them to ‘crawl’. Bots visit your website and then index (save) your web pages and files before listing them on search engine result pages.
If you don’t want certain pages or files to be listed by Google and other search engines, you need to block them using your robots.txt file.
You can check if your website has a robots.txt file by adding /robots.txt immediately after your domain name in the address bar at the top:

The URL you enter should have the format of either [domain.com/robots.txt] or [subdomain.domain.com/robots.txt] for subdomains.
How does it work?
Before a search engine crawls your website, it looks at your robots.txt file for instructions on what pages they are allowed to crawl and index in search engine results.
Robots.txt files are useful if you want search engines not to index:
- Duplicate or broken pages on your website
- Internal search results pages
- Certain areas of your website or an entire domain
- Certain files on your website such as images and PDFs
- Login pages
- Staging websites for developers
- Your XML sitemap
Using robots.txt files allows you to eliminate pages which add no value, so search engines focus on crawling the most important pages instead. Search engines have a limited “crawl budget” and can only crawl a certain amount of pages per day, so you want to give them the best chance of finding your pages quickly by blocking all irrelevant URLs.
You may also implement a crawl delay, which tells robots to wait a few seconds before crawling certain pages, so as not to overload your server. Beware that Googlebot doesn’t acknowledge this command, so instead optimise your crawl budget instead for a more robust and future-proof solution.
How to create a robots.txt file
If you don’t currently have a robots.txt file, it’s advisable to create one as soon as possible. To do so, you need to:
-
- Create a new text file and name it “robots.txt” – Use a text-editor such as the Notepad program on Windows PCs or TextEdit for Macs and then “Save As” a text-delimited file, ensuring that the extension of the file is named “.txt”
- Upload it to the root directory of your website – This is usually a root-level folder called “htdocs” or “www” which makes it appear directly after your domain name
- Create a robots.txt file for each sub-domain – Only if you use any sub-domains
- Test – Check the robots.txt file by entering yourdomain.com/robots.txt into the browser address bar
What to include in your robots.txt file
There are often disagreements about what should and shouldn’t be put in robots.txt files.

Robots.txt isn’t meant to hide secure pages for your website, therefore the location of any admin or private pages on your site shouldn’t be included in the robots.txt file as it, in fact, highlights their location to others. If you want to securely prevent robots from accessing any private content on your website then you need to password protect the area where they are stored.
Reminder: The robots.txt file is designed to act only as a guide for web robots and not all of them will abide by your instructions.
Robots.txt examples
Let’s look at different examples of how you may want to use the robots.txt file. Note that you can add comments to the file by proceeding a line with a hashtag (#).
Allow everything and submit the sitemap – This is the best option for most websites because it allows all search engines to fully crawl the site and index all its data. It even shows the search engines where the XML sitemap is located so they can find new pages very quickly as it checks the sitemap for changes regularly:
User-agent: *
Allow: /
#Sitemap Reference
Sitemap:http://www.example.com/sitemap.xml
Allow everything apart from one sub-directory – Sometimes you may have an area on your website which you don’t want search engines to show in the search engine results. This could be a checkout area, sensitive image files, an irrelevant part of a forum or an adult section of a website for example, as shown below. Any URL including the path disallowed will be excluded by the search engines:
User-agent: *
Allow: /
# Disallowed Sub-Directories
Disallow: /checkout/
Disallow: /secret-website-images/
Disallow: /forum/off-topic-random-chat/
Disallow: /adult-only-chat/
Allow everything apart from certain files – Sometimes you may want to show media on your website or provide documents but don’t want them to appear within image search results, social network previews or document search engine listings. Files you may wish to block could be any animated GIFs, PDF instruction manuals or any PHP files for example shown below:
User-agent: *
Allow: /
# Disallowed File Types
Disallow: /*.gif$
Disallow: /*.pdf$
Disallow: /*.PDF$
Disallow: /*.php$
Allow everything apart from certain webpages – Some webpages on your website may not be suitable to show in search engine results and you can block these individual pages as well using the robots.txt file. Webpages that you may wish to block could be your terms and conditions page, any page which you want to remove quickly for legal reasons, or a page with sensitive information which you don’t want to be searchable. Remember that people can still read pages that are disallowed by robot.txt file even if you aren’t directing them there from search engines. Also, the pages will still be seen by some scrupulous crawler bots:
User-agent: *
Allow: /
# Disallowed Web Pages
Disallow: /hidden-evil-contract-terms.html
Disallow: /blog/how-to-blow-up-the-moon
Disallow: /secret-list-of-bounty-hunters.php
Allow everything apart from certain patterns of URLs – Lastly, you may have an awkward pattern of URLs which you may wish to disallow which may duplicate content or be of no use within any search engine listings. Examples of URL patterns you may wish to block might be internal search result pages, leftover test pages from development, or subsequent pages after the first page of an eCommerce category page (see more on canonicalization):
User-agent: *
Allow: /
# Disallowed URL Patterns
Disallow: /*search=
Disallow: /*_test.php$
Disallow: /*?pageNumber=*
Putting it all together
Clearly, you may wish to use a combination of these methods to block different areas of your website. The key things to remember are:
- If you disallow a sub-directory then ANY file, sub-directory or webpage within that URL pattern will be disallowed
- The star symbol (*) substitutes for any character or number of characters
- The dollar symbol ($) signifies the end of the URL, without using this for blocking file extensions you may block a huge number of URLs by accident
- The URLs are case sensitive matched so you may have to put in both caps and non-cap versions to capture all
- It can take search engines several days to a few weeks to notice a disallowed URL and remove it from their index
- The “User-agent” setting allows you to block certain crawler bots or treat them differently if necessary, a full list of user agent bots can be found here to replace the catch-all star symbol (*).
If you are still puzzled or worried about the robot.txt file creation then Google has a handy testing tool within Search Console. Just sign in to Search Console (once setup) and simply select the site from the list and Google will return notes for you and highlight any errors.
Google has put together a ‘fishy’ looking overview of what’s blocked and what’s not blocked on their in-depth robots.txt file page:

What not to include in your robots.txt file (unless necessary)
Occasionally, a website has a robots.txt file which includes the following command:
User-agent: *
Disallow: /
This is telling all bots to ignore THE WHOLE domain, meaning no web pages or files would be listed at all by the search engines!
The aforementioned example highlights the importance of properly implementing a robots.txt file, so be sure to check yours to ensure you’re not unknowingly restricting your chances of being indexed by search engines.
Note: Whilst developing websites you may need to block the entire development area using this technique. Just be sure to not copy this disallow robots.txt file over when it all goes live!
Testing Your Robots.txt File
You can test your robots.txt file to ensure it works as you expect it to – it’s a good idea to do this even if you think it’s all correct.
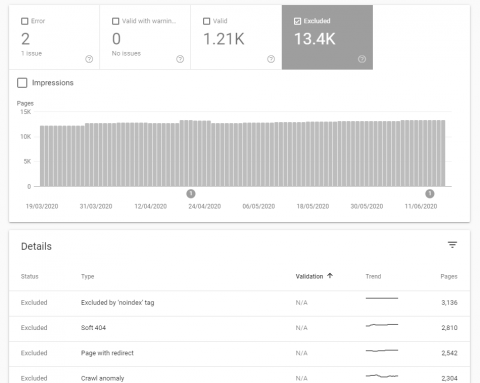
Enter Google Search Console (once setup) and go to the Coverage report on the left-hand-side which will show you current warnings, errors and other information about blocked pages on the website in the “Excluded” tab:
What happens if you have no robots.txt file?
Without a robots.txt file search engines will have a free run to crawl and index anything they find on the website. This is fine for most websites, but even then it’s good practice to at least point out where your XML sitemap lies so search engines can quickly find new content on your website, optimising their crawl budget – read more on this topic.
Bonus Fact
The robots.txt protocol was originally proposed by the legendary Martijn Koster who created the world’s first search engine, Aliweb:
Copyright – Web Design Museum